Java 基础
异常类
异常说明
如果出错,创建出一个异常类对象,抛出相关信息
继承关系
1 | Throwable |
Throw & Throws
位置不同
throw 是跟着异常对象 用在函数内
throws 跟着异常类 用在函数上
1
2throw new NumberFormateException();
int div(int a, int b ) throws Exception{}功能性
告知
- throws 告知可能会抛出异常
- throw 某部分执行到throw一定抛出具体异常对象 且功能结束,告知异常
消极处理
- 真正处理的是 函数的上级调用者 即:抛出 而不是用try catch 捕获
Finally
try中执行到return语句,不会直接return, 先计算return表达式,把结果保存到临时栈,再执行finally语句,之后才把临时栈的结果返回。
Java容器
容器模型
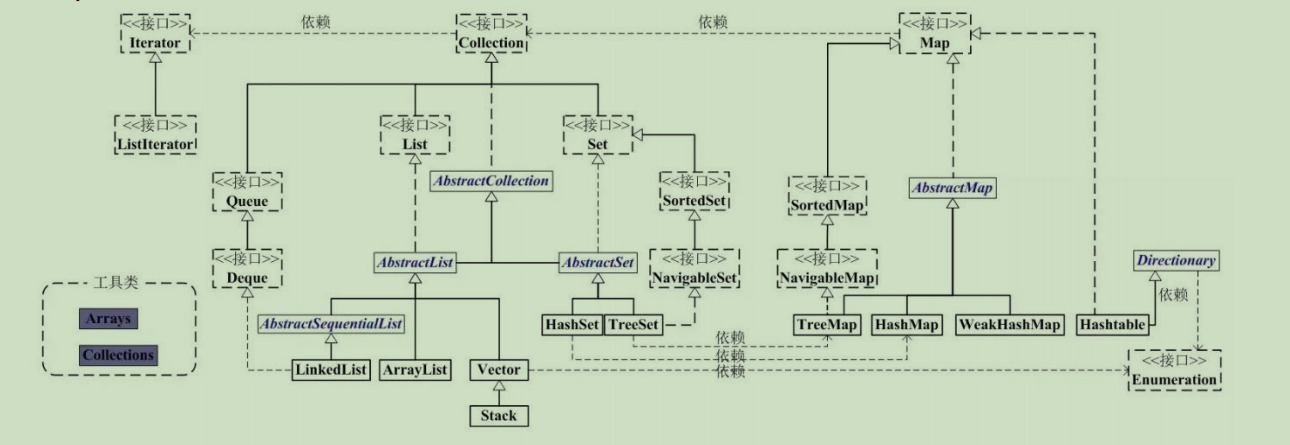
1 |
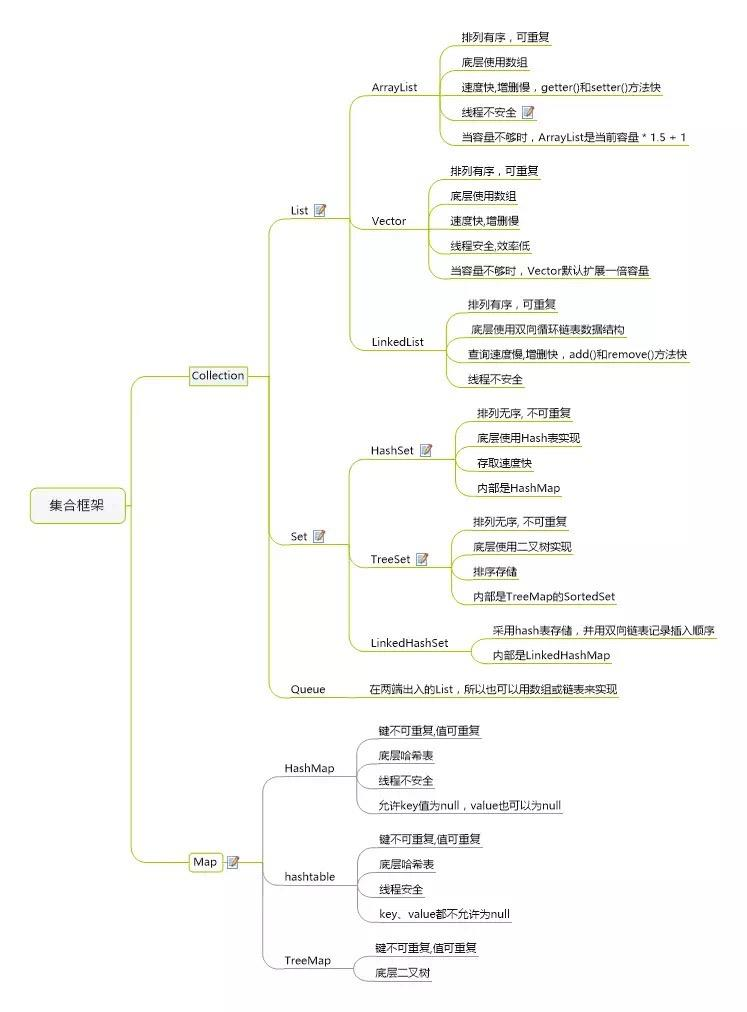
###
装箱&拆箱
int 与 integer区别: 数据类型与包装类区别
int:直接存数值 (初始化 = 0)
integer:引用指向这个对象(初始值 null)
integer a =1; -> integer a = integer.valueOf(1);
JavaI/O流
字符流
String 、StringBuild、 StringBuffer区别
- String 定义字符的数据变量
- StringBuild StringBuffer 都是拼接字符串,
- ”a“+”b“ string用到两个字符串变量 ,实际上只用一个把两个拼接,另一个释放就好。
- StringBuffer 采用同步机制 但效率慢 。。同理StringBuild
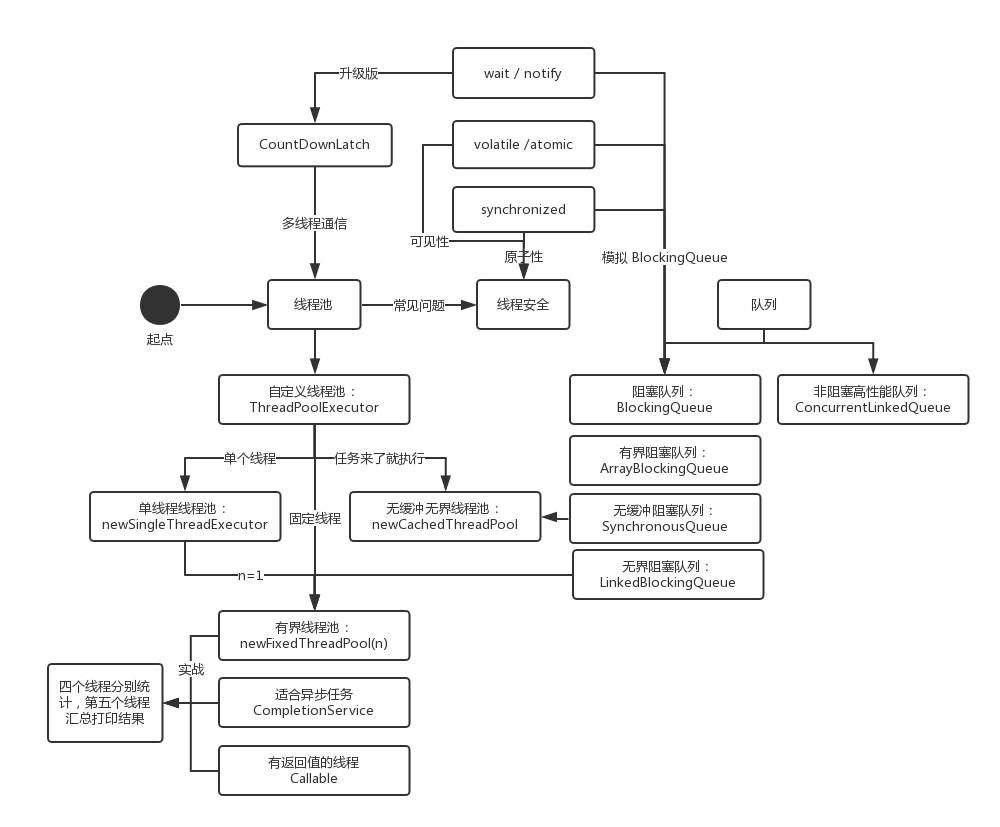
Java并发
线程内存模型
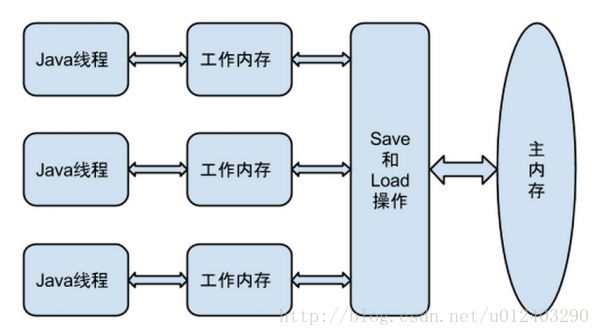
特点:
- 每个线程需要从主内存中 获取 变量的值
- 获取数据之后回放入自己的工作内存中,都是主内存拷贝的副本
- 线程间无法直接访问对方工作内存
线程工作状态
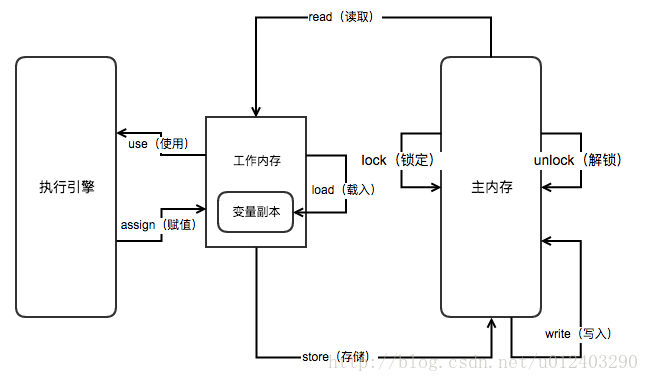
- lock(锁定):在某一个线程在读取主内存的时候需要把变量锁定。
- unlock(解锁):某一个线程读取玩变量值之后会释放锁定,别的线程就可以进入操作 。
- read(读取):从主内存中读取变量的值并放入工作内存中 。
- load(加载):从read操作得到的值放入工作内存变量副本中 。
- use(使用):把工作内存中的一个变量值传递给执行引擎 。
- assign(赋值):它把一个从执行引擎接收到的值赋值给工作内存的变量 。
- store(存储):把工作内存中的一个变量的值传送到主内存中 。
- write(写入):把store操作从工作内存中一个变量的值传送到主内存的变量中。
线程内部方法
单线程
1 | public class one extends Thread{ |
####
多线程
使用线程池
利用线程池管理线程的创建销毁,【缓存功能】
- 降低资源消耗
- 提高响应速度
- 线程可管理
常用线程池
- CacheThreadPool 无界 SynchronizedQueue 无缓存队列 接收任务直接处理
- FixedThreadPool 有界 LinkedBlokingQueue 列表阻塞队列 无界队列可缓存 读写分离
- SingleThreadPool 单一 LinkedBlokingQueue 指定队列 1
- ScheduledThreadPoll 定时周期
CachedThreadPool 无界线程池
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class CachedThreadPoolTest{
psvm{
ExecutorService exec = Executors.newCachedThreadPool();
for(20 times)
{
exec.execute(new WorkTask());
}
exec.shutdown();
}
}
//构造方法 参数 (线程数 最大线程数 时间片 单位时间 阻塞队列)
public static ExecutorService newCachedThreadPool(){
return new ThreadpoolExecutor(0,Integer.MAX_VALUE,60L,TimeUnit.SECONDS,new Sysnchronous<Runnable>());
}
FixedThreadPool 有界线程池
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class FixedThreadPoolTest{
psvm{
ExecutorService exec = Executors.newFixedThreadPool(3);
for(20 times)
{
exec.execute(new WorkTask());
}
exec.shutdown();
}
}
public static ExecutorService newFixedThreadPool(int nThreads){
return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
}
SingleThreadExecutor 单一线程池
1
2
3
4
5
6
7
8
9
10
11
12
13public class SingleThreadPoolTest{
psvm{
ExecutorService exec = Executors.newSingleTheadExecutor();
for(20 times)
{
exec.execute(new WorkTask());
}
exec.shutdown();
}
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));
ScheduledThreadPool 定时周期
1
2
3
4
5
6
7public class ScheduledThreadPool{
psvm{
ExectorService exec = new Exector.newScheduledThreadExecutor(3);
exec.execute(new WorkTask());
exec.shutdown();
}
}
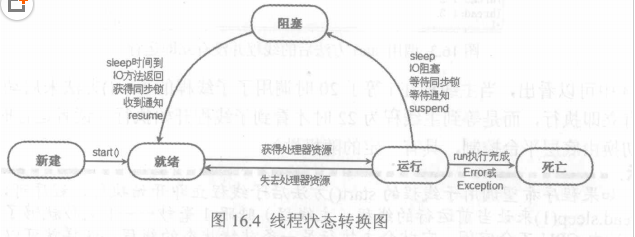
线程生命周期
- 新建 new创建线程 -> JVM分配内存 & 初始化成员变量的值。
- 就绪 线程对象调用start() 创建方法调用栈 & 程序计数器 等待调度运行。
- 运行 处于就绪状态线程获得CPU,开始执行run()方法的线程执行体。
- 阻塞
- 等待阻塞 run线程 执行 o.wait() jvm 会把线程放进等待队列
- 同步阻塞 run线程 想获取对象的同步锁,该锁被别的线程占用,jvm把线程放入锁池中(lock pool)
- 其他阻塞 Thread.sleep || t.join() || 发出IO请求
- 死亡
- 正常结束 run() || call() 方法执行完成
- 异常结束 线程抛出异常
- 调用stop stop()
乐观锁 & 悲观锁
容器并发
CopyOnWrite容器
当我们向容器中添加元素,先copy该容器,把数据添加到copy容器中,再将数组引用指向容器。
实现线程安全:
- volatile修饰数组引用:确保数组内存可见性。【内存可见】-》 copy数组引用。
- 对容器修改操作同步。同一时刻只有一条线程修改容器
- 修改容器复制容器:修改操作都在新数组上,原数组可以放心读。
优点
- 并发读,实现读写分离 (当前容器不会添加任何元素) 无需加锁
缺点
- 内存占用,使用两个容器
- 只能保证数据最终一致性,无法保证实时性
使用场景
读多写少,且不要求实时性
ConcurrentHashMap
线程安全的HashTable改进版(一个线程访问,其他统统阻塞),而ConcurrentHashMap实现分段锁机制。
分段锁原理
ConcurrentHashMap由多个Segment构成,每个Segment都包含一张哈希表。每次操作只将操作数据所属的Segment锁起来,从而避免将整个锁住。
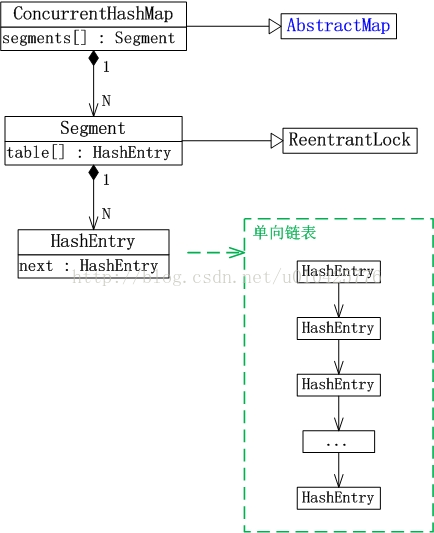
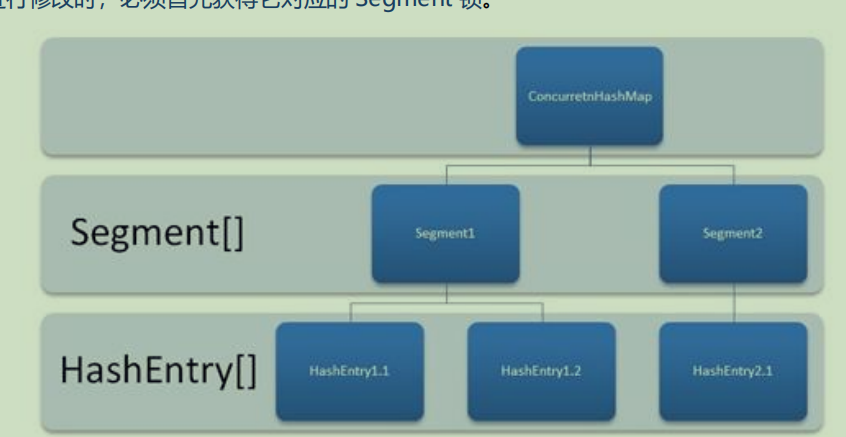
每个Segment守护一个HashEntry数组的元素,当对hashEntry数组数据修改是,必须先获取对应的Segment锁(就是分段锁机制)
ConcurrentHashMap内部包含了Segment数组,而每个Segment又继承自ReentrantLock,因此它是一把可重入的锁。
锁机制
脏读:a事务 读到 b事务 未提交的数据
解决
- 修改->排它锁,事务提交才释放,读取 ->共享锁
- 共享锁 (很多人可以读) 【有人想修改】 -》 排它锁 ,修改完毕后,其他人重新读数据时发现已经不同 ,(他运行事务未提交就释放共享锁) 导致不能避免 不可重复读
幻读: 同一事务,同样的操作读取两次,发现多了几条或者少了几条。 新增 删除的打扰
说明:
a事务 修改全表数据行, b事务插入一条新数据 a事务发现还有一条没有修改 ,就像发生幻觉一样。
事务T1:查询表中所有记录
-->事务T2:插入一条记录 -->事务T2:调用commit进行提交事务T1:再次查询表中所有记录
此时事务T1两次查询到的记录是不一样的,称为幻读。
解决:
- 采用范围锁,锁定检索范围只读。
不可重复读: 统一事务读取两次,发现内容不同
原因:执行select不加读锁(别人就改了)
解决:
- 推迟事务2执行,知道事务1提交或回退。
- 在事务提交时检查事务的顺序性,可以让事务2先提交,事务1后提交时,如果顺序是(1->2)则事务1会回退重读 (2 -> 1) 那没事了
- 读取数据加 共享锁 修改数据加排它锁 都是 事务提交才释放锁
丢失修改
- a事务读取数据,更新数据 b事务读取数据 更新数据 ,a先提交 ,b后提交 ,a的修改操作丢失了 解决+ 排它锁
事务隔离五种级别:
- TRANSACTION_NONE 不使用事务。
- TRANSACTION_READ_UNCOMMITTED 允许脏读。
- TRANSACTION_READ_COMMITTED 防止脏读,最常用的隔离级别,并且是大多数数据库的默认隔离级别。
- TRANSACTION_REPEATABLE_READ 可以防止脏读和不可重复读。
- TRANSACTION_SERIALIZABLE 可以防止脏读,不可重复读取和幻读,(事务串行化)会降低数据库的效率。
乐观锁CAS & 悲观锁
数据库
- 悲观锁 for update 行级锁
- 乐观锁 version字段 比较上次版本号 如果同 更新成功 ,不同,再(重复读)读 比较 写
jdk
- 悲观锁 sync
- 乐观锁 compose & Swap 原子类 内部使用CAS实现
思想 业务场景&实现方式
- 乐观锁 认为读多写少,遇到并发的可能性低,写数据线查看对应的版本号,自己加锁操作,之后比较版本号是否一致,之后写入。
CAP
- 高一致性c:分布式系统备份中,数据是否同一时刻都一直
- 高可用性a:集群节点故障,整体是否还能响应客户端请求
- 分区容忍性p:对通信时限的要求,
一致性算法
Paxos决议达成一致
想当learners的proposer去acceptor投简历
- 角色:Proposer、Acceptor、Learners
- 阶段:
- 准leader确定 【proposer的N提案proposer请求,acceptor的v承诺】。
- leader确定 【proposer的多数票选[N,V]acceptor请求 ,送给acceptor,则答应成为learners】。
ZAB原子消息广播协议
有王国的带纸和广播的人
三大步骤
- 崩溃恢复:leader服务器崩溃,ZAB进入恢复状态,选举新的leader
- 数据同步:新leader会与过半以上服务器数据同步,ZAB退出崩溃恢复模式,进入消息广播
- 消息广播:有新的服务器加入,会自动找到消息广播的leader,与它进行数据同步工作,进leader服务器数据发送到其他服务器。
Raft
###
Java网络通讯
NIO
NIO分为阻塞和分蛛丝啊量
数据库原理
垂直切分&水平切分
垂直切分:
- :+1:表与表的io争夺
- :no_entry:单表数据量增长压力
水平切分: 相反
1 | 产品表 订单表 用户表 |
索引
索引种类
普通索引 index[userName] on (username(length))
唯一索引 unique [indexName] on (username(length)) 索引列唯一
主键索引 primary key (id)
组合索引 name, city, age建到一个索引里 alter table mytable add index name_city_age(name(10), city, age);
相当于 mysql组合最左前缀
- username,city,age
- username,city :select * from mytable where username =”admin” city =”cc”
- username: select * from mytable where username=‘ss”
索建立时机
<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE才会使用索引
city & age 建立索引 ,mytable 的username也要建立
1 | select t.Name |
索引不足
up 查询速度
down 表更新速度 :insert 、update delete 需要维护主表之外还要同步保存索引文件,在聚集索引层面上说就是需要维护这个平衡树,每次的更新都会破坏原有树的状态,需要重新梳理树的结构,如果数据量很大,更新表可能就开始变得困难
聚集索引 (主键索引)
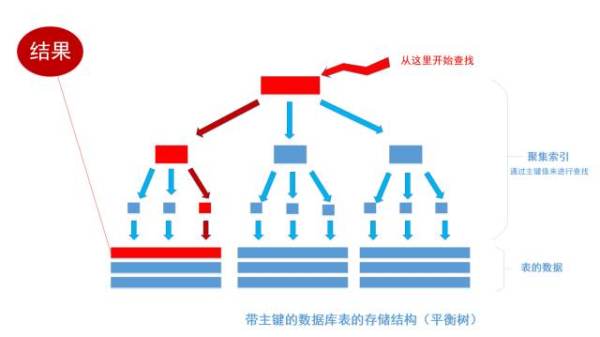
非聚集索引 (单一索引 普通索引 组合索引)
可以通过非聚集索引所提供的记录查到对应的聚集索引(主键) 然后再用主键查。
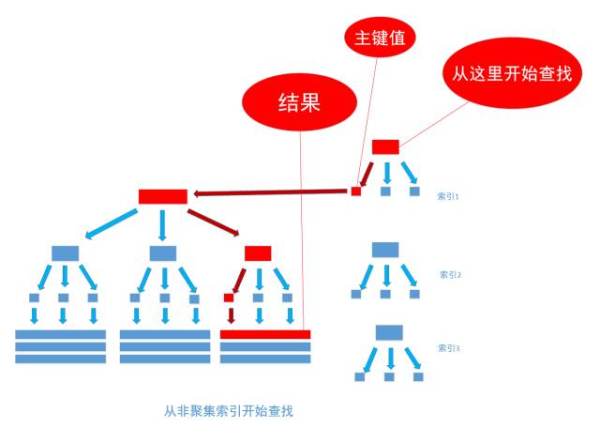
无论有什么方式查表,都会利用主键以聚集索引的方式来定位数据,聚集索引(主键)是通往真实数据的唯一通道。
索引占用磁盘索引文件
1 | create table mytable( |
MyISAM&InnoDB引擎
区别
- 事务 锁InnoDB 支持 外键、事务、行级锁 。MyISAM(不支持)
- 读写性能MyISAM读性能up,写性能up(除了有索引update的InnoDB)
- 索引数据MyISAM索引和数据分开,索引压缩 -》非聚集索引 b+数检索算法检索,找到对应的数据域的值(是主键的地址) ;InnoDB索引和数据时紧密联系
- delete table mytabl InnoDB不会重新建立表, 是一行一行删
- 锁表 锁行InnoDB可能锁全表(而不是行级锁)当 like%aaa% 扫不确定范围 ; 和 where 条件没有主键时。
使用
- 执行大量的INSERT或UPDATE操作需要事务 : InnoDB
- 大量的SELECT查询读多写少的项目,可以考虑使用MyISAM
三范式
原子性
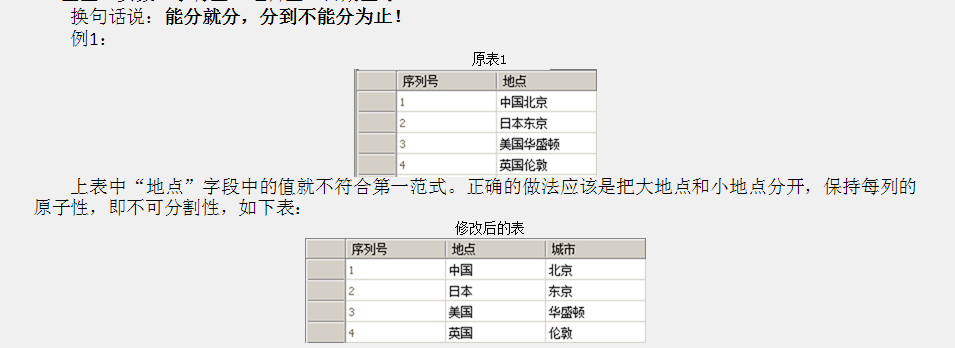
2NF
一张表里描述了两个事情:学生信息、课程信息
姓名、年龄 -> 学号 学分 -> 课程
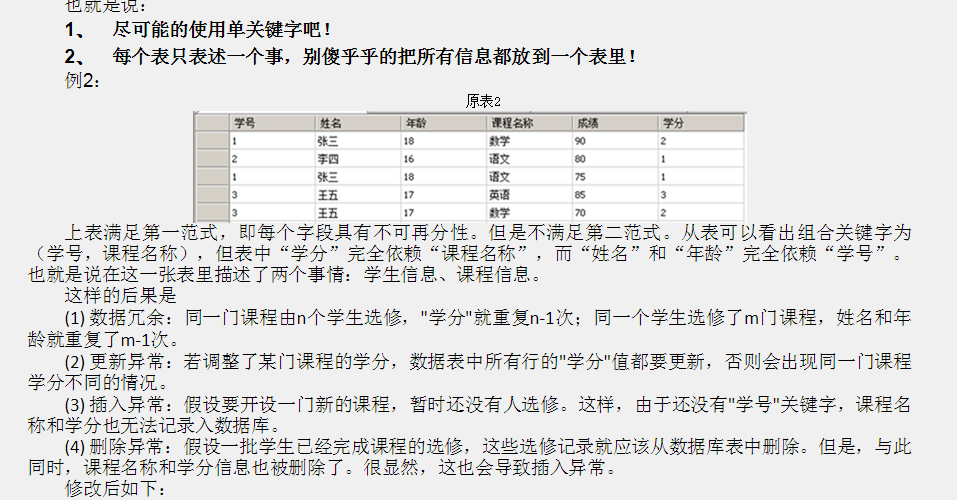
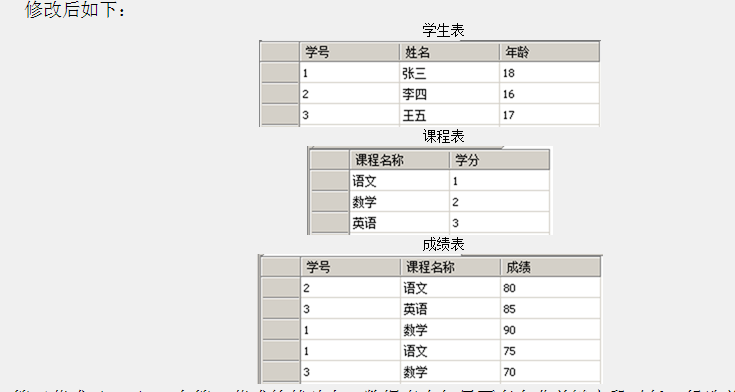
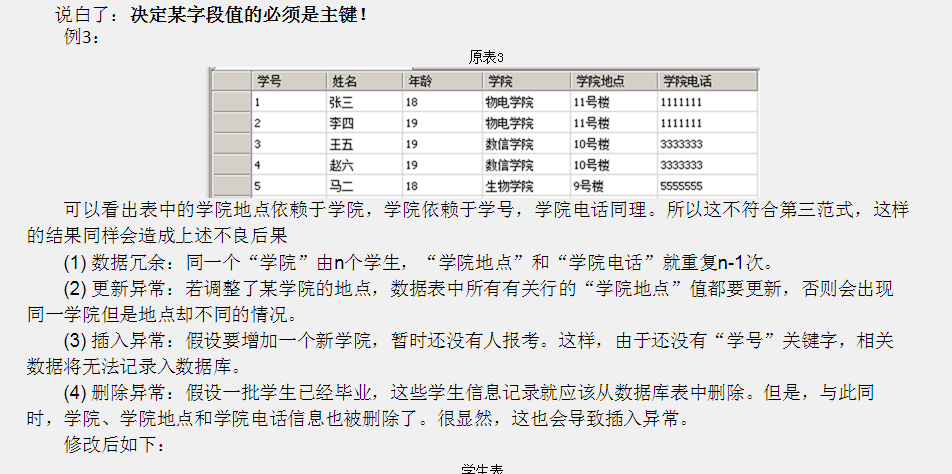
3NF
某个字段必须是主键
学院地址、学校电话 -> 学院 学院 -》学号
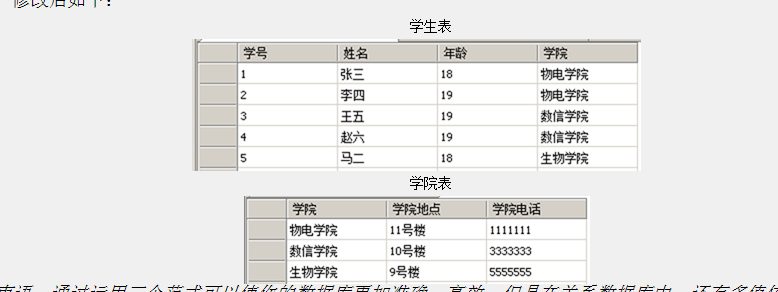
其他
== equal hashcode区别
- == equal 都是判断引用地址是否相同
- string equal 就是 1.判断是否为string类型 2.遍历每个char字符
- 重写equal可以判断内容是否相同
- hashcode 更多应用在set 无重复数字,(每增加一个 就要和n-1个数字equal的缺点)。
- 每个数都有对应的 hashcode 映射到哈希表中,(每个数有对应的坑和他的坑号码)
- 比较只要看他手上的坑号码是否相同,不同就不等,同就equal判断内容。
接口和抽象类
抽象类通过继承来使用
接口通过实现类使用
抽象类可以提供抽象方法和实现方法
接口类实现方法需要用default定义 lamdba表达式
强制类型转换错误
1 | short s1 = 1; 把 整数1 转换为 short类型 |
length方法
- 数组长度 .length 属性
- String获取长度 length()方法
- 集合获取长度 size()方法
- 文件获取长度 length()方法
介绍数据库索引
1、索引的种类4,索引生效时刻,主键、组合,普通,聚集索引和非聚集索引
线程安全问题
线程安全需要你使多个线程安全有序的访问修改同一个资源,而不会造成冲突。(修改丢弃、脏读、不可重复读

