Java基础二
其他
Equals & hashcode
为什么重写equals还要重写hashcode
引入了hashCode()这个方法,只是为了提高equals效率
保证相同对象有相同的hashcode
(在hashMap中 key相同 hashcode value 不同 (不会被覆盖)
key相同 hashcode value 相同 (会覆盖)
(在hashSet中 同理 因为hashcode不同 导致(本来应该相同的对象不出现)结果出现了
两个对象hashCode相同 ,它们并不一定相同(这里说的对象相同指的是用eqauls方法比较)
不重写的情况下,= 比较基本数据类型的值 、 equals 调用 hashcode 返回对象的地址 比较,
重写情况equal下,比较方式发生了变化, equal 调用 hashcode 返回对象的地址比较 之后再比较对象内的成员变量的值是否相等,但是对象a 对象b 成员变量值相等,但是hashcode未重写的情况下还是直接判断内存地址,所以需要并重写hashcode。
Object若不重写hashCode()的话,hashCode()如何计算出来的?
hashCode 相当于key,value 对应 哈希值和散列码 散列码就是哈希函数根据哈希值和对象映射出来的唯一一个值,作为内存地址, 例如 数组 5 f(x) = y%5 数字是 6 则 存在 1的位置上,还有哈希冲突(线程探测、二次探测、伪随机探测、链地址发、 公共溢出区 )
- == 作用与基本的数据类型 作用于应用类型变量(比较指向对象内存地址)、 equals 不 作用于基本数据类型(没重写就是比较引用类型的变量所指向的对象的地址)
总结:
== 是比较基本数据类型的值 ,**数据类型和变量的值都一致时才返回true。**如果是引用数据类型的话(不可变类String(字符常量池 字符相同有相同的地址 如果是连接 String连接后面的字符串值在编译时确定下来,不能直接引用常量池中的) Integer 等包装类已经重写equal和hashcode (Integer -127 128 有缓存机制 两个Integer才相等 ,如果Integer 和 int 会自动拆箱 两个int相等)
只有当它们指向同一个对象时才返回true。
1 | String str1 = "a"; |
java8新特性
Lambda表达式 &函数式接口
Lambda表达式 函数作为参数 传递给某个方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Arrays.asList("a","b","c").forEach(e -> sout(e));
//复杂语句块
Arrays.asList("a","n","c").forEach( e ->{
sout(e);
sout(e);
});
//应用类成员和局部变量
final String spearator = ",";
Arrays.asList("a","b","c".forEach(
(String e) -> sout(e + spearator);
));
//返回值
Arrays.asList("a","b","c").sort((e1,e2) -> e1.compareTo(e2));
Arrays.asList("a","b").sort((e1,e2) ->{
int result = e1.compareTo(e2);
return result;
})Lambda表达式良好兼容 -> 函数接口,(只有一个函数的接口) 该接口可以隐式转换Lambda表达式 默认方法
1
2
3
4
5
6
7
8
9//函数式接口
public interface Functional{
void method();
//默认方法
// 高可用 该接口新增方法时 不需要在 已实现该接口的类也添加方法
default void defaultMethod(){...};
}方法引用 和 landba表达式紧密联系 -> java构造方法紧密 简洁
优点:简洁、易并行计算
缺点:可读性、不容易调试
数据类型
基本数据类型
byte 1 short 2 int 4 long 8 | char 2 boolean float 4 double 8
封装类
好处
应用数据类型
ArrayList 、Vector、LinkedList ||| HashSet TreeSet ||| HashMap HashTable LinkedHashMap TreeMap
自动拆装箱
自动装箱
1
2Integer i = 100;
Integer i = Integer.valueOf(100);
自动拆箱
1
2int one = i;
int one = i.intValue();
在-128~127内的情况 (封装类有更多的重写方法)
封装类的缓存机制
1
2
3
4
5
6
7
8
9
10
11
12
13Integer i = 100; Integer cache = new Integer(100)
Integer b = 100; Integer i b = cache
//( i == b ) == true;
Integer a = 200; -相当> Integer a = new Integer(200)
Integer b = 200; -相当> Integer b = new Integer(200)
// (a == b) == false;
在 -128 到 127 Integer.valueOf(int i )
返回的是缓存对象 所以 i b 指的是同一个对象
String s1 ="abc";
String s2 ="abc"; s1 = s2 true
String s3 = new String("abc");
String s4 = new String("abc"); s3 != s4 true
值传递和引用传递
这个要和不可变类(没有 不允许) & 可变类挂钩(拥有改变自身的引用类型 类似setX)
基本类型和引用类型
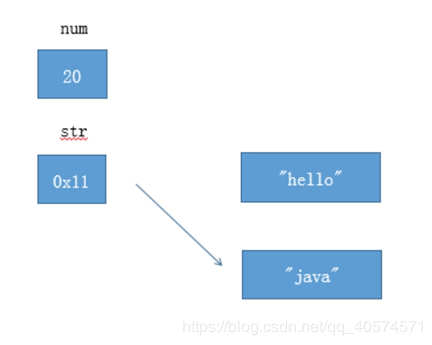
num是基本类型,变量直接保存值。
str是引用类型,变量保存对象的地址
赋值运算符(=)的作用
1
2num = 20;
str = "java";num是基本类型, 改变变量的值
str是引用类型,改变变量的地址
调用方法 -> 赋值操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24void foo(int value) { 基本类型
value = 100; //num = 20
} //value = 20
//value = 100
foo(num); // num 没有被改变
没有提供改变自身方法的引用类型
void foo(String text) { //str = 0x11"java"
text = "windows"; //text= 0x11"java"
//text= 0x12"windwos"
}
foo(str); // str 也没有被改变
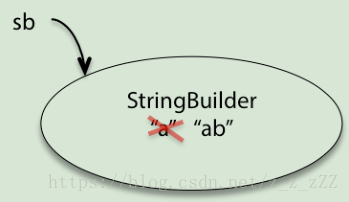
StringBuilder sb = new StringBuilder("iphone");
void foo(StringBuilder builder) {
builder.append("4"); 提供了改变自身方法的引用类型
}
foo(sb); // sb 被改变了,变成了"iphone4"。
StringBuilder sb = new StringBuilder("iphone");
void foo(StringBuilder builder) { 提供了改变自身方法的引用类型,
但是不使用,而是使用赋值运算符。
builder = new StringBuilder("ipad");
}
foo(sb); // sb 没有被改变,还是 "iphone"。

总结:
- 基本数据类型传值:形参不会修改实参。
- 引用类型传引用,形参实参指向同一个内存地址,所以对参数的修改会影响到实际的对象。
- String、Integer,Double 等Immutable(不可变类)特殊处理,可以理解为传值,最后的操作不会修改实参对象。
ArrayList & Array
- Array:定长数组,长度不变
- ArrayList:不定长数组,(相当数组的二次封装),加入泛型机制,存储基本数据类型的封装类(加入时会自动装箱) ArrayList
这样
Java Immutable机制
mutable immutable优缺点
| mutable(引用) | immutable(String+封装类) | |
|---|---|---|
| 优点 | 减少数据拷贝,效率高 | 为了保证数据不变,需要大量临时拷贝,浪费空间 |
| 缺点 | 内部数据会改变 | 线程安全,内部数据不会改变。常量池 |
| 值传递 | 引用传递 |
不可变特性主要为了满足常量池、线程安全、类加载的需求。合理使用不可变类可以带来极大的好处。
例如
StringBuilder
String
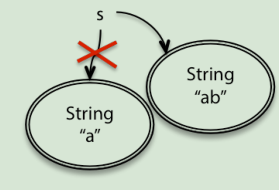
1 | String s = "a"; |
构造Immutable类
- filed成员被private final修饰。
- 不提供setX
- 使用final修饰自定义类,确保该类不会被重写。
- 如果类中的成员为mutable类型,初始化该类或者get该成员时,使用深拷贝。确保类immutable。
1 | public final class MyImmutable{ |
int 和 Integer 有什么区别
- int 基本数据结构 、 Integer 是包装类 ,包装类内有大量方法提供对该类型的数据进行操作,也对equals hashcode进行重写,Integer -127 128 有缓存机制, 所以 可以equals 但是 超过不行。包装类因此可以自动拆装箱,另外ArrayList这些容器因为不定长,支持泛型,所以只支持包装类。
- 两者都是不可变类,final类方法 没有set 拿去没有final需要clone ,线程安全,符合常量池、类加载需求,他们没有对应的引用传递
- 自动拆装箱 语法糖 java自动帮我们转换:装箱 Integer.valueOf() 拆箱:Integer.intValue()所以要注意无意识的拆装箱 (数据量大开销大)
- 值缓存(有范围)Integer i1 = 1; ||Integer i2 = Integer.valueOf(2); || Integer i3 = new Integer(3); 1 2 就用到值缓存,而三没有 (1 自动装箱 同二一致)String 默认都只会将绝对值较小的值放入缓存
- 线程不安全的:基本数据类型时线程不安全(封装类是不可变类 所以线程安全)AtomicInteger、AtomicLong
& &&
- 对于:& – > 不管怎样,都会执行”&”符号左右两边的程序
- 对于:&& – > 只有当符号”&&”左边程序为真(true)后,才会执行符号”&&”右边的程序。
Synchronize锁和lock
Synchronize种锁状态
- 锁当前对象:同步代码块、非静态同步函数(使用this锁)
- 锁当前类class:静态函数同步方法锁
区别 自动门 和 手动门
- synchronized java内置关键字、lock是java类
- 判断锁的状态
- 自动、手动释放锁(synchronize 执行完、异常 释放)(lock在finally中手工释放锁(unlock()方法释放锁)否则会死锁
- synchronize就是悲观锁、local就是乐观锁(尝试得到锁 得不到就不等了)
- synchronize可重入 不可中断、非公平 、lock 可重入 、可中断、可公平
- synchronize适合小量代码块 、lock适合大量同步代码块。
Volatile
- 可见性:被volatile 修饰的变量在被线程拿到后,如果a线程修改该变量,会通知内存修改相应的变量,这样其他线程拿取volatile就是a线程修改后的变量。
- 有序性:禁止指令重排,(指令重排是cpu为了提高执行效率,首先执行响应快的部分代码,而像byte[1024*1024]需要IO指令则会推后执行。
- 不能保证原子性:
Final关键字
自己理解:用在不可变类上面(String、Integer 等这些包装类、所以不能用set获取值,想拿到值就必须重新copy一份,因此也出现了StringBuilder这类,因此只能值引用,也应如此他线程安全符合常量池,值缓存、类加载等需求)
- 修饰区域:修饰类说明该类不能被继承,该类private的方法会被隐式指定为final方法,成员变量需另外指明。
- final成员变量:(局部成员变量懒汉式加载,使用前初始化即可)final必须在定义时或构造器中初始化赋值 且不能再赋值
1 | String a ="hello2"; |
Wait
暂停线程会释放锁,wait方法的线程必须调用notify notifyAll才能唤醒。
String为啥不可变
我的理解:String被final修饰,String 的valueOf需要内部调用copy开辟新内存空间,满足常量池需求,线程安全
不可变: 对象不可动,那就只能复制其地址, 保证效率和安全只是赋值一次。
常量池需求

运行String对象缓存HashCode:字符串不变性保证了hash码的唯一性。
安全 : babalala
Object类
- clone()
- equals()
- getClass()
- hashCode()
- notify() notifyAll()
- toString()
- wait()
重载和重写
- 重载只要考虑参数(类型和数量) 重写 太严格了。
Static
方便在没有创建对象情况下调用(方法、变量),不需要依赖对象来访问,只要类加载了,就可以通过类名来访问。
负载因子是2^n
哈希取模不如位移运算: hash%length==hash&(length-1) 而且length是2的幂。

